System Design - Item Recommender System Design
This post is about a simple item(job) recommendation system that I’ve learned and coded recently. I am trying to expand it a little and therefore record the system design based on the tiny project.
Functional requirement
- User is able to search jobs based on location and keywords;
- User is able to favorite jobs;
- User is able to get recommended jobs.
Functional design
The complex part is how should the system recommend jobs to users. There are a few recommendation algorithms that can be selected:
Content based filtering
This algorithm is based on the simple principle: if a user like one item, then he/she might also like a similar item or an item with similar properties. It is purely based on the items’ characteristic. Sometimes, Amazon or Youtube will recommend similary products or vedios to you if you search one item before. This algorithm is normally used when the system doesn’t have much information of the users and their behavior, but has enough information on the item/products. This algorithm recommends similar items to the users based on users’ favorite/purchase history.
User based filtering (collaborative filtering I)
This algorithm is based on users’ behavior: If two users like the same items/products in the past, then they might also like the same items/products in the future. Thus, if two users have common interest on some items/products, then they might like each other’s other items/products. Youtube/Amazon normally say “Viewer of this vedios/product also viewed XXX”. It is based on this approach.
Item based filtering (collaborative filetering II)
This algorithm is a mix of content based filtering and user based filtering. It uses item’s similarity, but the similarity of item is not based on the item’s characteristics but users’ rating. For example, if User A, B, C like Item 1, and User A, B also like Item 2, then item 1 and 2 might be similary, and thus recommend to User C.
Since we have no user data, only job data, we choose content based filtering, which is based on the users’ favorite history. The problem is how to characterize a job to find their similarity. When people search for job, there are a few critical things that they are interested: location, title, and job description. A job could be chracteristized by a series of keywords. When a user favorite a job, the system saves the jobs and its keywords. If the user wants to get recommendation jobs, the system pulles out the users favorite history, and uses the keywords to search from job database.
Keyword extraction
A simple and yet relatively accurate approach to extract keywords is TF-IDF (Term Frequency - Inverse Document Frequency). TF is the frequency of a word in a document, IDF is the inverse of the frequency of documents that contains the word to all documents. Inuatively, if a word appears more times in a document, then it is naturally a keyword. But some words appears all the time in all of the documents, e.g., “the”, “of”, “is”, etc. To remove these common words, IDF is calcuated as a weighting factor. IDF = (number of total documents) / (number of document containing a word).
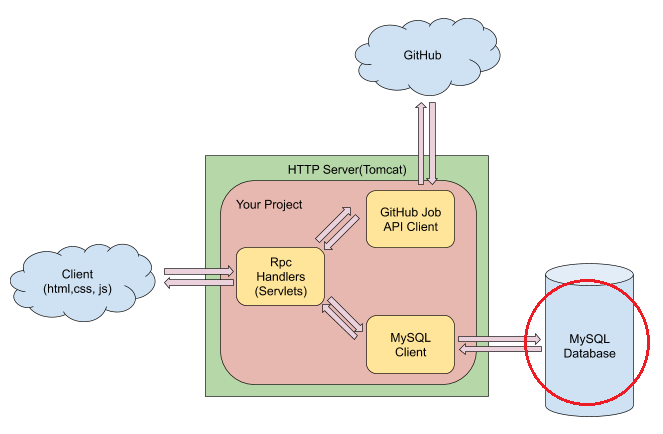
API design
To fulfill the functional requirement, the system could use a number of different algorithms
User Register && Login
POST /register
data :{
userId: xxxx
password: xxx
name: xxx
}
POST /login?userId=%s&password=%s
Search Job
POST /search?location=%s&keyword=%s
search(location, keyword)
Favorite Job
POST /history?userId=%s&itemId=%s
favorite(userId, itemId)
Unfavorite Job
DELETE /history?userId=%s&itemId=%s
unfavorite(userId, itemId)
Get Favorite Jobs
GET /history?userId=%s
getFavoriteItems(userId)
Get recommend Jobs
GET /recommendation?userId=%s
getRecommendationJob(userId)
Database design
Schemas
We need a table for User, and Job Item at least. Since we don’t have job source, we have to get jobs from third party, e.g., Github jobs, we don’t need to store the job description, but just a url is enough. We also need a table to store users favority history, and keywords for each of the job item.
user
| user_id | password | first_name | last_name | | ——- | ——– | ———- | ——— |
items
| item_id | title | location | url | | ——- | —– | ——– | — |
history
| user_id | item_id | timestamp | | ——- | —– –| ——— |
keywords
| item_id | keyword | | ——- | ——- |
Scalability, Availability
Load balancer
Since this system is relatively small, no load balancer or replica has been used.
Cache
Every time when user search jobs, get recommended jobs, the system has to acquire database or third-party job portal. In memory cache could be used to improve search speed. What could/should be cached?
- The search results from third-party job portal. This results could be put in cache for a few seconds.
- The favorite items could be cached. One way is to save them to cache, when user retrieves favorite items, and when user favorite new items, invalidate the cached favorite list.
Write through cache
Data is written into database and cache at the same time. Slow comparing the other two methods because two times writting is required.
Write around cache
Data is written to database only. Data is copied to cache after user retrieves it from database.
Write back cache
Data is written to cache only, cache is managed to copy data to database. Risk of data loss if cache crashes.
We choose to use write around method.