Distributed System - MIT 6.824 Raft Lab 4B
Lab 4B
Lab 4B is to build a key/value storage that shards or partitions. Each of the shard/partition has several replica servers that based on Raft to maintain strong consistency. Each replica group is only responsible of a subset of the key/values. Main functions:
- Each group services a certain number of shards, that support get, put and append to the particular shards;
- A shardmaster from Lab 4A manages congiruation changes, i.e., adding new groups, remove groups, etc, and allocate shards accordingly;
- Each group acquire the shardmaster for configuration change, and migrates shards based on the new shard arrangement.
- Client/clerk send request to all the groups until the operation is completed.
High level operation sequence
How to detect configuration change?
Server acquire shardmaster and if the current config is less than the latest config, update the current to next config. The update should be one by one, i.e., if the old one has not completed updating, even the shard master has new config, the server should wait until the previous finished.
Who should detect configuration change, all servers or only leaders?
To maintain strong consistency, only leader need to detect configuration change, and send to raft for updating all followers. So that all servers in the group maintain the same information.
What server should do when it detects configuration change?
- The group should update its service shards, if some shards still in this group, than the server should continue to service these servers. This can be achieved by maintaining a service shard in the group.
- The server should push shards that no longer belongs to the group, or pull shards from other groups.
Implementation
New State
Obviously, we have to add shard information for each of the key/value pair, i.e., the shard that this key/value belongs to. Because Lab 4B uses a key to shard map, and the total number of shard is fixed. I used a simpler approach that represent each shard as a map data in the server. This way, it is easier to move the complete shard in or out of the database.
Because the server need to response quickly if it does not service a shard, we can maintain a map for service shards.
Once the server detect configuration change, it then start to migrate in or out data, create two maps for the migration-out data and migrate-in data.
Further, the server has to keep the information of the current configruation, because it need to compare with the new configuration.
New state:
shardData Shardstore //store shard key value pair
departData Shardstore //store KVs that waiting for other groups to fetch, first key is config+shard
pullinStatus map[int]string //status of incomming shard data
serviceShards map[int]bool //shards currently in services
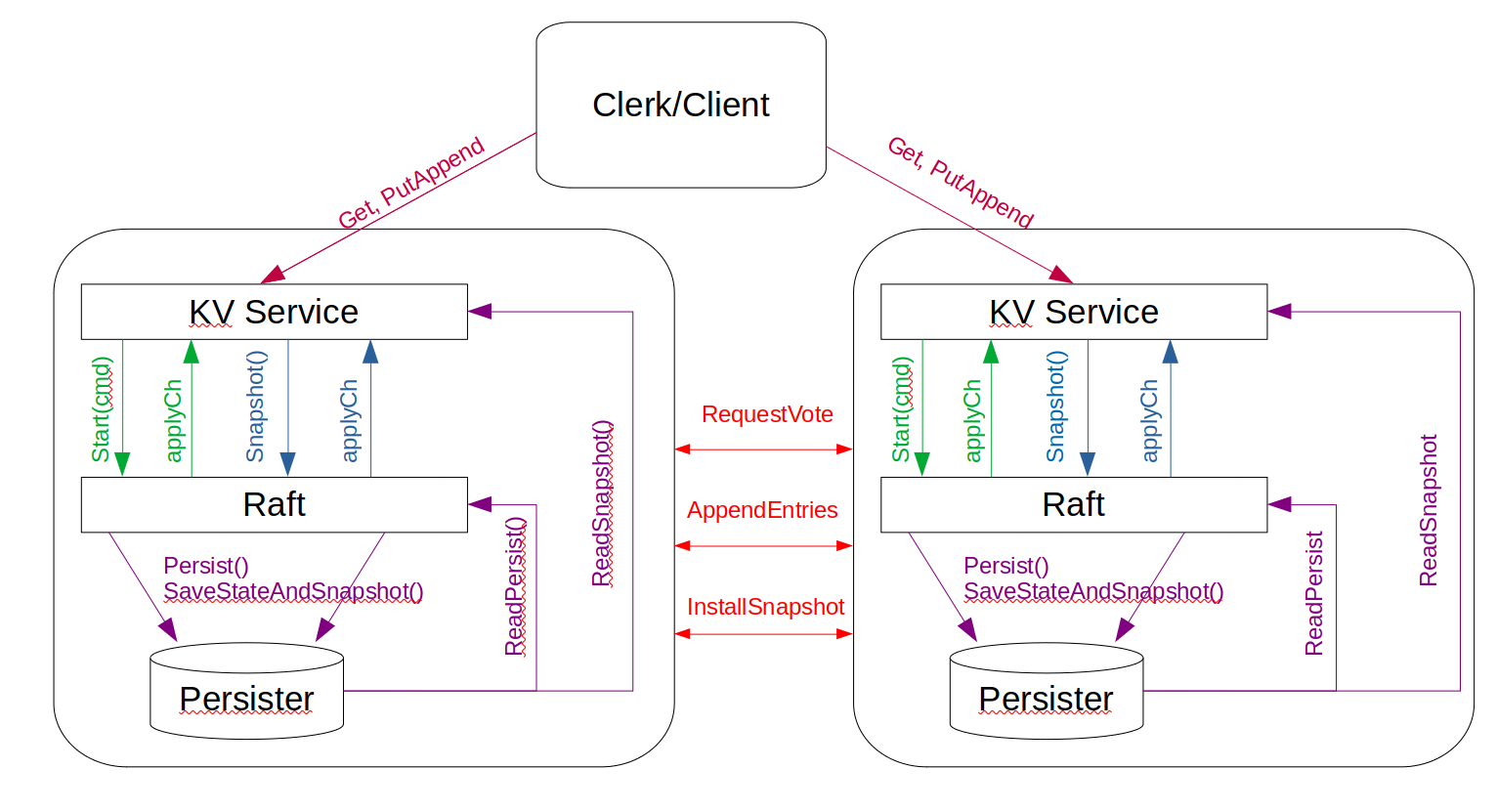
Configuration Update
The Server need to constantly acquire shard master for the latest config and update. This requires a backend thread. Thinking how this process should be. What if a client request (Get, Put/Append) comes at the same time as configuration change? How to address concurrency?
Raft is the answer. Similar to client request, send configuration change to raft too, and raft will address which is first. Double check whether the request is in the current server, and disregard request that not service in this server anymore. That means, only leader need to acquire configuration change.
func (kv *ShardKV) checkNewConfig() (bool, shardmaster.Config) {
kv.mu.Lock()
defer kv.mu.Unlock()
nextConfig := kv.sm.Query(kv.curConfig.Num + 1)
// if pull in Status is not empty, that means, previous config update is still in process
// and it should not proceed to update the new config
if len(kv.pullinStatus) == 0 && nextConfig.Num > kv.curConfig.Num {
return true, nextConfig
}
return false, kv.curConfig
}
//Threads detect config update
func (kv *ShardKV) configUpdateThread() {
/* every operation from the group leader itself need a client Id for Op struct.
It is used to detect operation duplication, because the same config might have multiple Op send to Raft,
while it is waiting agreement.
*/
clientId := hash(strconv.Itoa(kv.gid) + CFG_UPDATE)
for !kv.killed() {
if kv.assertLeader() {
if ok, newCfg := kv.checkNewConfig(); ok {
DPrintf("Group %d, Server %d, New Config: %v, ", kv.gid, kv.me, newCfg)
op := Op{OpType: CFG_UPDATE, Config: newCfg}
op.ClientId = clientId
op.OpId = int64(newCfg.Num)
if !kv.isDuplicateRequest(op.Shard, op.ClientId, op.OpId) {
op.Index, op.Term, _ = kv.rf.Start(op)
}
}
}
time.Sleep(100 * time.Millisecond)
}
}
Note that in the above code, I reused the Op struct for sending information to Raft. The Op need a ClientId and OpId. For this operation, ClientId is itself, and because duplicate request could be sent to raft, a OpId is set to the new configuration Num. So the same configuration num will only be updated once. Another field that critical is OpType, this is used to tell servers that this is a config update operation, which means Op struct brings in the new configuration information.
When raft returned and all server agrees the configuration change, the servers should go to update its configue.
What server should do when it receives configuration update operation?3
The main tasks for the servers is to update its shard states. That includes:
- It need to update its service shards. Remove the shards that not service in this config from serviceShards.
- Set up and initilize the shards status that need to be pulled in in pullinStatus.
- Move the shards that need to be pushed to outshardData waiting for other groups to pull them.
Note that all the above operation is performed after raft agreement, so all the servers in the group has the same copy. The current implementation uses pull mode, that is, the server will pull shards from other groups that owns it. Another way is push mode, that is, the server pushes shards to other groups.
// update config and service shards, set up pullin status, and depart data
func (kv *ShardKV) updateConfig(op *Op) {
newConfig := op.Config
if newConfig.Num != kv.curConfig.Num+1 {
return
}
prevConfig := kv.curConfig
kv.curConfig = newConfig
configId := kv.curConfig.Num
kv.serviceShards = make(map[int]bool)
for shard, newGID := range kv.curConfig.Shards {
if configId == 1 || (prevConfig.Shards[shard] == kv.gid && newGID == kv.gid) {
kv.serviceShards[shard] = true
} else if prevConfig.Shards[shard] != kv.gid && newGID == kv.gid {
kv.pullinStatus[shard] = WAIT
} else if prevConfig.Shards[shard] == kv.gid && newGID != kv.gid {
outshardData := kv.shardData.RemoveShard(strconv.Itoa(shard))
cfgShard := strconv.Itoa(configId) + "-" + strconv.Itoa(shard)
kv.departData.PutShard(cfgShard, outshardData)
}
}
op.Error = OK
}
How to migrate shard data?
The basic procedure is group leader send pull request (RPC call) to target server. The target server reply the shard key/value. When the requester receives the reply, it send the shard data to raft, and all the group update the shard data. After reply the shard key/value, the target server cannot delete this shard from its state. Because the RPC reply might fail, or the receiving server might already broken down. Therefore, the target server has to receive confirmation from the request server before it can delete the depart shard. This is a two phase mechanism.
Firstly, when server receives request shard, it should respose with the shard data if it is the first phase request. If it is the second phase request, it should send a operation to all its follower to delete the shard data from departShard.
func (kv *ShardKV) RequestShardRPC(args *ShardRequestArgs, reply *ShardRequestReply) {
if !kv.assertGID(args.TargetGID) {
reply.Err = ErrWrongGroup
return
}
if !kv.assertLeader() {
reply.Err = ErrWrongLeader
return
}
kv.mu.Lock()
// first phase to pull data
if args.RequestPhase == 0 && args.Config.Num <= kv.curConfig.Num {
shardRd := make(map[string]string)
srdRd, _ := kv.requestRecord.GetShard(strconv.Itoa(args.Shard))
for ky, val := range srdRd {
shardRd[ky] = val
}
cfgShard := strconv.Itoa(args.Config.Num) + "-" + strconv.Itoa(args.Shard)
srdData, ok := kv.departData.GetShard(cfgShard)
if ok {
kvData := make(map[string]string)
for key, val := range srdData {
kvData[key] = val
}
reply.KVData = kvData
reply.ShardRecord = shardRd
reply.Err = OK
} else {
reply.Err = ErrWrongGroup
}
}
kv.mu.Unlock()
// second phase to delete depart data from the current group
if args.RequestPhase == 1 {
op := Op{OpType: DELETE_OUTWARD_SHARD, Shard: args.Shard, Config: args.Config}
clientId := hash(strconv.Itoa(kv.gid) + strconv.Itoa(args.Shard) + op.OpType)
op.ClientId = clientId
op.OpId = int64(args.Config.Num)
if !kv.isDuplicateRequest(op.Shard, op.ClientId, op.OpId) {
op.Index, op.Term, _ = kv.rf.Start(op)
}
reply.Err = OK
}
}
There are two status for each of the shards that need to be pulled, WAIT and COMMITED. WAIT means that the server is still waiting for the shard. COMMITED means the server received the shard. If the status is WAIT, then the server need to request the shard again, if it is COMMITED, then the server should send signal back to the target server so that it could delete the shard. If the target server reply OK back, that means this server could delete the status from the map, so that it will not be queried again.
func (kv *ShardKV) requestShards() {
configId := kv.curConfig.Num
prevCfg := kv.sm.Query(configId - 1)
// if shard is still in pullinStatus
for shard, status := range kv.pullinStatus {
rGID := prevCfg.Shards[shard]
switch status {
// if the shard status is WAITING
case WAIT:
args := ShardRequestArgs{SourceGID: kv.gid, TargetGID: rGID, Shard: shard, RequestPhase: 0, Config: kv.curConfig}
go func(vgid int, vshard int) {
for _, server := range prevCfg.Groups[rGID] {
srv := kv.make_end(server)
var reply ShardRequestReply
ok := kv.sendRequestShard(srv, &args, &reply)
// if reply is OK, send to raft for agreement
if ok && reply.Err == OK {
op := Op{OpType: SAVE_INWARD_SHARD, KVData: reply.KVData, ShardRecord: reply.ShardRecord, Shard: vshard, Config: args.Config}
clientId := hash(strconv.Itoa(kv.gid) + strconv.Itoa(vshard) + op.OpType)
op.ClientId = clientId
op.OpId = int64(configId)
if !kv.isDuplicateRequest(op.Shard, op.ClientId, op.OpId) {
op.Index, op.Term, _ = kv.rf.Start(op)
}
}
}
}(rGID, shard)
// if it is commited, send commit phase to target group
case COMMITED:
args := ShardRequestArgs{SourceGID: kv.gid, TargetGID: rGID, Shard: shard, RequestPhase: 1, Config: kv.curConfig}
go func(vgid int, vshard int) {
for _, server := range prevCfg.Groups[rGID] {
srv := kv.make_end(server)
var reply ShardRequestReply
ok := kv.sendRequestShard(srv, &args, &reply)
// if reply is OK, send to Raft for agreement and so that the pullinStatus is deleted
if ok && reply.Err == OK {
op := Op{OpType: DELETE_INWARD_STATUS, Shard: vshard, Config: args.Config}
clientId := hash(strconv.Itoa(kv.gid) + strconv.Itoa(vshard) + op.OpType)
op.ClientId = clientId
op.OpId = int64(configId)
if !kv.isDuplicateRequest(op.Shard, op.ClientId, op.OpId) {
op.Index, op.Term, _ = kv.rf.Start(op)
}
}
}
}(rGID, shard)
}
}
}
A backend thread is maintained to check the pull data status and send pull data request if there are still items in it.
// threads to continously monitor the inward shard status and if not commited to pull data from its group in old config
func (kv *ShardKV) shardsUpdateThread() {
for !kv.killed() {
if kv.assertLeader() {
kv.mu.Lock()
if len(kv.pullinStatus) > 0 {
kv.requestShards()
}
kv.mu.Unlock()
}
time.Sleep(100 * time.Millisecond)
}
}
There are seven operations that need to be agreed by Raft, each of them corresponding to different operation types. The PUT, APPEND, GET are similar to the previous KV Server. The new operation types are:
- CFG_UPDATE: Configuration update. Server polles the new configuration from shardmaster, and update the serviceShards, pullinStatus, and move the outgoing shards to outshardData waiting for other group to pull them.
- SAVE_INWARD_SHARD: Server saves the shard from Op to its KV store, and update serviceShards to true, and pullinStatus to COMMITED.
- DELETE_INWARD_STATUS: Server deletes the shard from pullinStatus map. This is to inform server the shard has been installed in the server, and no pull request is needed.
- DELETE_OUTWARD_SHARD: Server deletes departing shards that stored.
func (kv *ShardKV) updateServiceState(op *Op) {
if kv.lastAppliedIndex >= op.Index {
return
}
kv.lastAppliedIndex = op.Index
kv.lastAppliedTerm = op.Term
switch op.OpType {
case PUT:
kv.putToDatabase(op)
case APPEND:
kv.appendToDatabase(op)
case GET:
kv.getFromDatabase(op)
case CFG_UPDATE:
kv.updateConfig(op)
case SAVE_INWARD_SHARD:
kv.saveShard(op)
case DELETE_INWARD_STATUS:
kv.deletePullinStatus(op)
case DELETE_OUTWARD_SHARD:
kv.deleteDepartShard(op)
}
kv.updateRequestRecord(op)
}
The basic procedures for data migration is as follows:
- Leader server detectes configuration change;
- Leader sends Raft agreement with opType == CFG_UPDATE to followers about configuration change;
- Servers receive agreement on the configuration change, and go to updateConfig(), which updates new config with new shards that services, shard need to be pulled and shard need to be pushed;
- Leader detectes that new shards need to be pulled (with shard status == WAIT), and send request to other groups to pull shards.
- When leader receives shards from other groups, it sends Raft agreement with opType == SAVE_INWARD_SHARD and shard data to its followers.
- Servers receive SAVE_INWARD_SHARD, it saves the shard data to its KV store and update the shard status to COMMITED.
- Leader detectes incomming shard is commited, it sends the second request to the same group inform it that the shard data is commited.
- If leader receives OK, it sends Raft agreement to its followers with opType == DELETE_INWARD_STATUS to inform them to delete the incomming shard status.
- At the same time, when leader receives request shard RPC call. If it is the first request, it replies by attach the shard data. If it is the second request, it sends Raft agreement to its followers with opType == DELETE_OUTWARD_SHARD.
- When Servers receive opType == DELETE_OUTWARD_SHARD, they deletes the shard data from its KV store.
- Leader keeps request shards if it does not receive from other group. Only after all shards are fulfilled, the leader could goes to the next configuration update.
These conclude Lab 4B. Complete Code: github